Meta AI Researchers Introduced a Scalable Byte-Level Autoregressive U-Net for Language Modeling
Language modeling plays a crucial role in natural language processing, allowing machines to predict and generate text that mimics human language. Over the years, language models have advanced from statistical methods to neural architectures and, more recently, large-scale transformer-based systems.

One of the challenges in language modeling is the heavy reliance on token-based and transformer models, which can be computationally expensive and inefficient for tasks at the byte level or across multiple languages. Techniques like Byte Pair Encoding help control sequence lengths but introduce inconsistencies between languages.
Challenges in Language Modeling
Transformers, while accurate, suffer from scalability issues due to their quadratic complexity. Alternative approaches like sparse attention aim to address this, albeit sometimes at the cost of simplicity or performance.

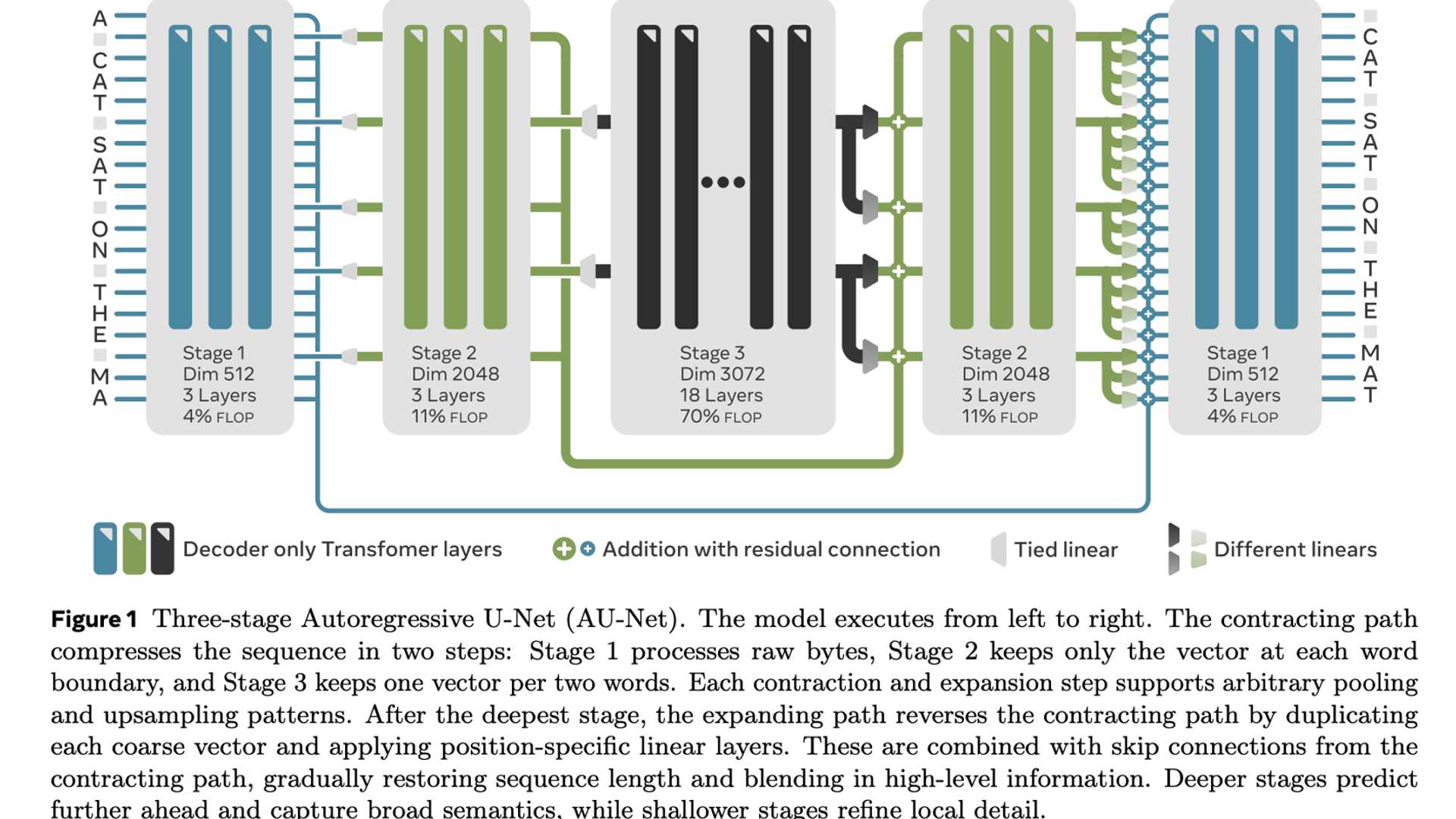
Researchers from FAIR at Meta, TAU, INRIA, and other institutions introduced a novel Autoregressive U-Net (AU-Net) that combines elements of convolutional U-Net designs with autoregressive decoding processes. Unlike transformer systems, AU-Net operates directly on bytes without the need for tokenization.
The AU-Net architecture utilizes multiple scale stages to reduce and reconstruct input sequences using convolutions with strides. During training, segments of the input sequence are predicted in a masked fashion to maintain the autoregressive property.
Performance and Benchmarks
Experimental results demonstrate AU-Net's strong performance across different tasks. In benchmark tests like Enwik8 and PG-19, AU-Net outperformed standard transformer models in terms of bits per byte and long-context language modeling, respectively.
For more information, you can refer to the paper and GitHub page.









